Here we will partition recreational landings data from NOAA Fisheries’ Marine Recreational Information Program (MRIP), a standardized, peer-reviewed suite of recreational fishing surveys used to produce catch and effort estimates for quota monitoring and stock assessment in the United States. MRIP is a standardized survey suite that employs a complex statistical sampling design stratified across time, regions of the coast, and different fishing modes, which allows the intercept data to be scaled up by effort estimates to calculate total catches.
3.1 Data access and upload
Data are downloaded directly from the Miami server using the files provided to SERO for ACL monitoring. The current location is: M://SFD/SECM-SFD/ACL/2025_Jun23_MRIP_MRFSS/. The landings are in FES MRIP and the units are in pounds whole weight.
# clear workspacerm(list =ls())# read in data fileload("data/mrip_fes_rec81_25wv2_23June25.RData") # most recent file on SFD serverhead(dat)
REC_ACL_MRIP_FES_ID YEAR MONTH WAVE SUB_REG NEW_ST NEW_STA NEW_MODE NEW_MODEN
1 73407425 1989 NA 4 6 9 NC 4 Priv
2 73407426 1989 NA 4 6 9 NC 4 Priv
3 73407427 1989 NA 4 6 9 NC 4 Priv
4 73407428 1989 NA 4 6 9 NC 4 Priv
5 73407429 1989 NA 4 6 9 NC 4 Priv
6 73407430 1989 NA 4 6 9 NC 4 Priv
AREA_X NEW_AREA NEW_AREAN FL_REG NC_REG DS NEW_SCI
1 5 5 Inshore NA S MRIP Centropristis striata
2 5 5 Inshore NA N MRIP Centropristis striata
3 2 2 Ocean>3mi NA N MRIP Centropristis striata
4 2 2 Ocean>3mi NA S MRIP Centropristis striata
5 1 1 Ocean<=3mi NA N MRIP Centropristis striata
6 1 1 Ocean<=3mi NA S MRIP Centropristis striata
NEW_COM SP_CODE SPECIES_ITIS SPECIES AB1 B2
1 black sea bass 8835020301 167687 34181.4033 121019.1368
2 black sea bass 8835020301 167687 795.8612 4445.0527
3 black sea bass 8835020301 167687 549.5390 2919.4840
4 black sea bass 8835020301 167687 71823.2390 24548.2535
5 black sea bass 8835020301 167687 415.7642 87.5928
6 black sea bass 8835020301 167687 48728.5632 11859.6428
A B1 LBSEST_SECWWT LBSEST_SECSOURCE SAMPLE_SIZE_USED
1 31761.4755 2419.9278 11457.8425 srysmwa 41
2 584.4155 211.4457 266.7782 srysmwa 41
3 549.5390 0.0000 484.4319 srysmwa 119
4 33343.1844 38480.0546 63313.9276 srysmwa 119
5 415.7642 0.0000 294.0623 srysmwa 71
6 40585.0152 8143.5480 34464.8156 srysmwa 71
AVG_LEN AVG_WGT SRYSMWA_AVG_LEN SRYSMWA_AVG_WGT SRYSMWA_SAMPLE_SIZE
1 203.4572 0.3352069 203.4572 0.3352069 41
2 203.4572 0.3352069 203.4572 0.3352069 41
3 296.2590 0.8815243 296.2590 0.8815243 119
4 296.2590 0.8815243 296.2590 0.8815243 119
5 261.9949 0.7072816 261.9949 0.7072816 71
6 261.9949 0.7072816 261.9949 0.7072816 71
SRYSMWA_FLAGGED SRYSMW_AVG_LEN SRYSMW_AVG_WGT SRYSMW_SAMPLE_SIZE
1 NA 269.2563 0.7310037 231
2 NA 269.2563 0.7310037 231
3 NA 269.2563 0.7310037 231
4 NA 269.2563 0.7310037 231
5 NA 269.2563 0.7310037 231
6 NA 269.2563 0.7310037 231
SRYSMW_FLAGGED SRYSM_AVG_LEN SRYSM_AVG_WGT SRYSM_SAMPLE_SIZE SRYSM_FLAGGED
1 NA 259.7694 0.6948228 556 NA
2 NA 259.7694 0.6948228 556 NA
3 NA 259.7694 0.6948228 556 NA
4 NA 259.7694 0.6948228 556 NA
5 NA 259.7694 0.6948228 556 NA
6 NA 259.7694 0.6948228 556 NA
SRYS_AVG_LEN SRYS_AVG_WGT SRYS_SAMPLE_SIZE SRYS_FLAGGED SRY_AVG_LEN
1 270.955 0.8099641 982 NA 269.1276
2 270.955 0.8099641 982 NA 269.1276
3 270.955 0.8099641 982 NA 269.1276
4 270.955 0.8099641 982 NA 269.1276
5 270.955 0.8099641 982 NA 269.1276
6 270.955 0.8099641 982 NA 269.1276
SRY_AVG_WGT SRY_SAMPLE_SIZE SRY_FLAGGED SR_AVG_LEN SR_AVG_WGT SR_SAMPLE_SIZE
1 0.8085211 1703 NA 303.6871 1.050403 46055
2 0.8085211 1703 NA 303.6871 1.050403 46055
3 0.8085211 1703 NA 303.6871 1.050403 46055
4 0.8085211 1703 NA 303.6871 1.050403 46055
5 0.8085211 1703 NA 303.6871 1.050403 46055
6 0.8085211 1703 NA 303.6871 1.050403 46055
SR_FLAGGED S_AVG_LEN S_AVG_WGT S_SAMPLE_SIZE S_FLAGGED VAR_B2 VAR_AB1
1 NA 344.4373 1.364082 305089 NA 4072492794 310099094
2 NA 344.4373 1.364082 305089 NA 2866289 258947
3 NA 344.4373 1.364082 305089 NA 0 0
4 NA 344.4373 1.364082 305089 NA 105731413 534702898
5 NA 344.4373 1.364082 305089 NA 0 0
6 NA 344.4373 1.364082 305089 NA 22265768 286196169
SA_LABEL GOM_LABEL REC_ACL MIGRA_GRP AGG_MODEN JURISDICTION PS_REG
1 Snapper Grouper 1 Private State 6
2 Snapper Grouper 1 Private State 5
3 Snapper Grouper 1 Private Federal 5
4 Snapper Grouper 1 Private Federal 6
5 Snapper Grouper 1 Private State 5
6 Snapper Grouper 1 Private State 6
COUNCILREG GFMC_FMP SAFMC_FMU LBSEST_SECGWT AGGR_AREA AREA FIRST_MONTH
1 6 Y 9710.0360 NA NA
2 5 Y 226.0832 NA NA
3 5 Y 410.5355 NA NA
4 6 Y 53655.8708 NA NA
5 5 Y 249.2054 NA NA
6 6 Y 29207.4709 NA NA
LAST_MONTH ALT_FLAG CHTS_CL CHTS_H CHTS_RL CHTS_WAB1C CHTS_WAB1H MODE_FX
1 NA 0 0 0 0 0 0 7
2 NA 0 0 0 0 0 0 7
3 NA 0 0 0 0 0 0 7
4 NA 0 0 0 0 0 0 7
5 NA 0 0 0 0 0 0 7
6 NA 0 0 0 0 0 0 7
NEW_SEASN SEASON
1 NA
2 NA
3 NA
4 NA
5 NA
6 NA
#apply(dat[2:18], 2, table, useNA = "always")# confirm nomenclature for dolphin and subset by species --------------------------table(dat$NEW_COM[grep("dolphin", dat$NEW_COM)])
dolphin
9377
table(dat$NEW_SCI[grep("dolphin", dat$NEW_COM)])
Coryphaena hippurus
9377
d <- dat[which(dat$NEW_COM =="dolphin"), ]#apply(d[2:18], 2, table, useNA = "always")d <- d[which(d$YEAR <2025), ] # take out 2025 because incomplete year tot <-tapply(d$LBSEST_SECWWT, d$YEAR, sum, na.rm = T)
3.2 Separate Gulf and Atlantic recreational landings
Now we filter the data set to separate out the Gulf versus Atlantic landings.
# codes for WFL regions: 1 (NW FL Panhandle- Escambia to Dixie co.), 2 (SW FL Peninsula- Levy to Collier co), 3 (FL Keys- Monroe co.)# subregional codes: 6 is Atlantic and 7 is Gulftable(d$FL_REG, d$SUB_REG, useNA ="always")
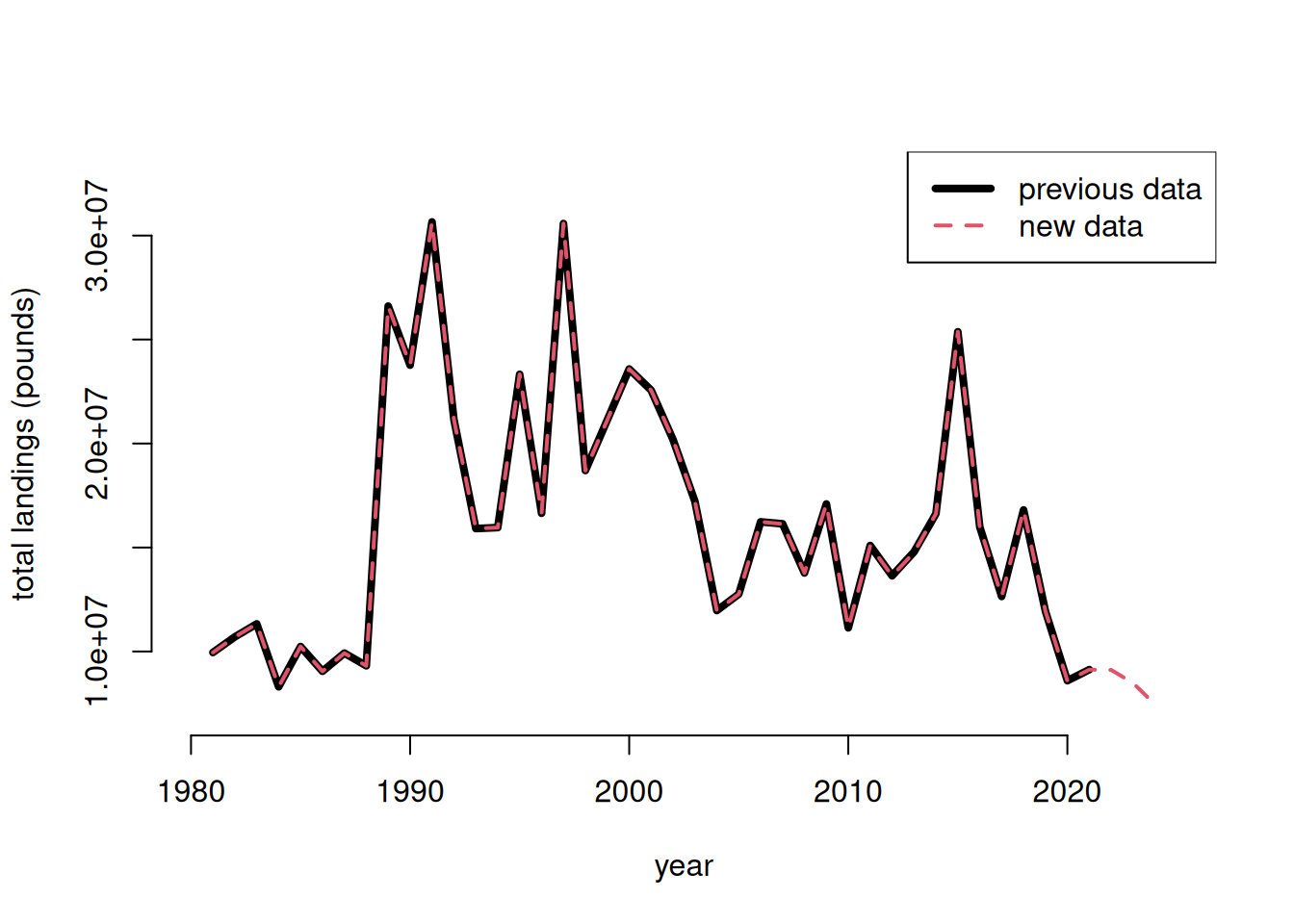
Now we can summarize the total dolphin landings in weight for the U.S. Atlantic, and compare to previous values sent for quota monitoring. We see that the values are almost identical.
# summarize by year and compare --------------------------tot1 <-tapply(d1$LBSEST_SECWWT, d1$YEAR, sum, na.rm = T)#head(tot1)old <-read.csv("data/RecreationalDolphinLandings_SAandGOM_MLarkin.csv", skip =6)plot(old$Year, old$ATL, type ="l", xlab ="year", ylab ="total landings (pounds)", lwd =4, xlim =c(1980, 2025), ylim =c(7*10^6, 3.3*10^7), bty ="n")lines(as.numeric(names(tot1)), tot1, lwd =2, col =2, lty =2)legend("topright", c("previous data", "new data"), col =c(1, 2), lwd =c(4, 2), lty =c(1, 2))
3.3 Partition landings by area and sector
Now we will partition out the total landings according to the dolphin MSE areas. The areas are as follows:
FLK: Florida Keys to Indian River County County (FL)
NCFL: Brevard (FL) to Southern NC (South of Hatteras)
NNC: Northern NC (North of Hatteras to NC/VA border)
VBM: Virginia to Maine
# separate out 4 regions --------------------------d1$region <-"VBM"# select for FLK# FL_REG codes: 4: SE FL- Miami-Dade to Indian River County.; 5: NE FL- Brevard to Nassau Countytable(d1$FL_REG, d1$NEW_STA, useNA ="always")
, , = FLK
CT DE FLE FLE/GA FLW GA MA MD NC NJ NY RI SC VA
0 0 1022 0 568 0 0 0 0 0 0 0 0 0
N 0 0 0 0 0 0 0 0 0 0 0 0 0 0
S 0 0 0 0 0 0 0 0 0 0 0 0 0 0
, , = NCFL
CT DE FLE FLE/GA FLW GA MA MD NC NJ NY RI SC VA
0 0 312 1794 0 54 0 0 0 0 0 0 644 0
N 0 0 0 0 0 0 0 0 0 0 0 0 0 0
S 0 0 0 0 0 0 0 0 338 0 0 0 0 0
, , = NNC
CT DE FLE FLE/GA FLW GA MA MD NC NJ NY RI SC VA
0 0 0 0 0 0 0 0 0 0 0 0 0 0
N 0 0 0 0 0 0 0 0 420 0 0 0 0 0
S 0 0 0 0 0 0 0 0 0 0 0 0 0 0
, , = VBM
CT DE FLE FLE/GA FLW GA MA MD NC NJ NY RI SC VA
14 114 0 0 0 0 20 125 586 108 73 62 0 165
N 0 0 0 0 0 0 0 0 0 0 0 0 0 0
S 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# summarize by Gulf and Atlantic regions and check against total -----------------------atl <-tapply(d1$LBSEST_SECWWT, list(d1$YEAR, d1$region), sum, na.rm = T)GULF <-tapply(dg$LBSEST_SECWWT, dg$YEAR, sum, na.rm = T)table(rownames(atl) ==names(GULF))
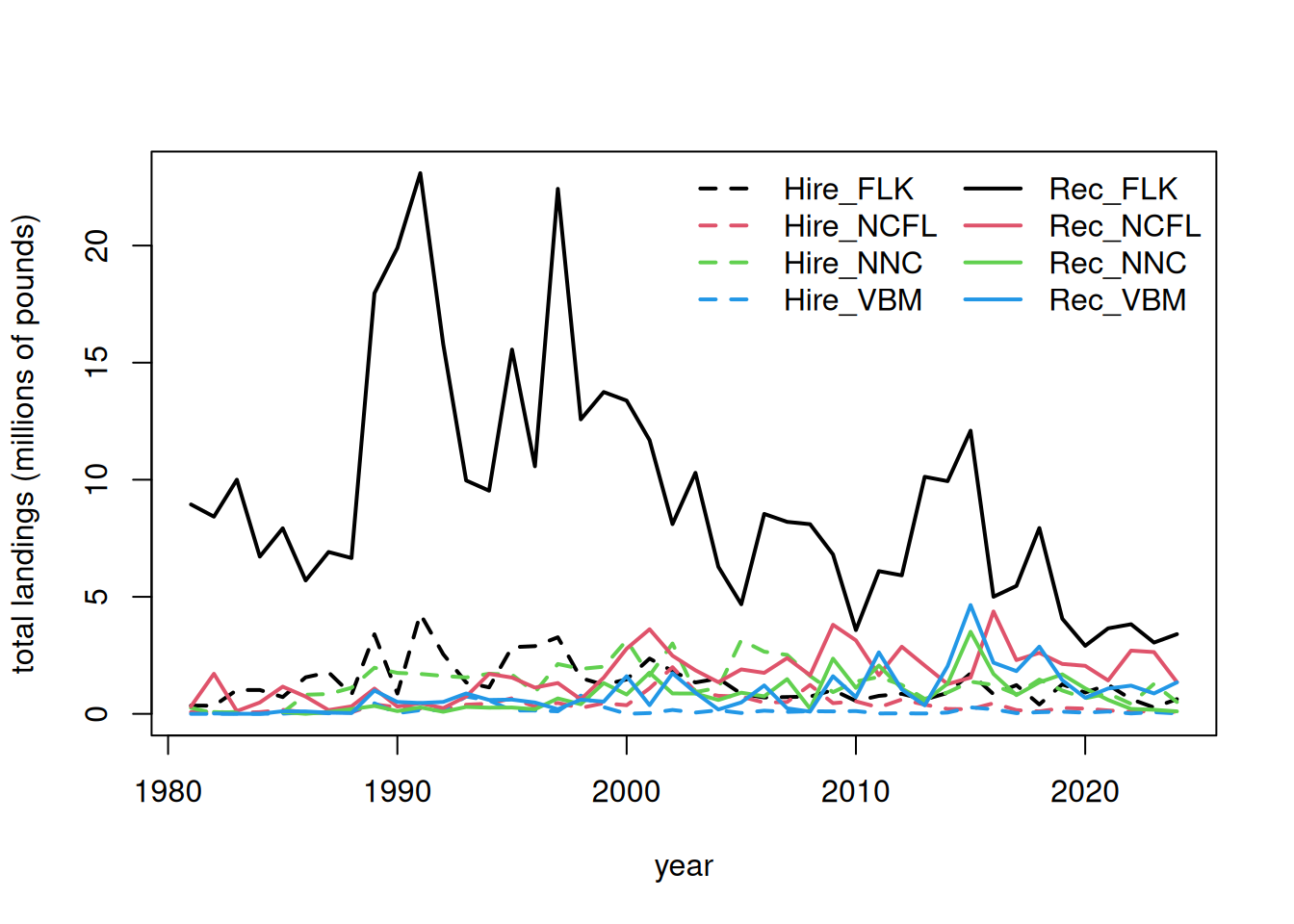
Now we will separate out the landings by recreational sector and plot the totals by region and sector.
# separate out by for hire vs. private rec --------------------------d1$sector <-"ForHire"d1$sector[which(d1$NEW_MODEN =="Shore")] <-"Rec"d1$sector[which(d1$NEW_MODEN =="Priv")] <-"Rec"table(d1$sector, d1$NEW_MODEN, useNA ="always") # check classification
matplot(rownames(fin), fin/10^6, lty =c(rep(2, 4), rep(1, 4)), col =rep(1:4, 2), type ="l", lwd =2, xlab ="year", ylab ="total landings (millions of pounds)")legend("topright", colnames(fin), lty =c(rep(2, 4), rep(1, 4)), col =rep(1:4, 2), lwd =2, ncol =2, bty ="n")
# check that totals matchcor(rowSums(fin, na.rm = T), tot1)
[1] 1
mean(rowSums(fin, na.rm = T) - tot1) # very tiny differences
[1] 4.233284e-11
Here are the landings (in pounds) for years 1981 to 2024.
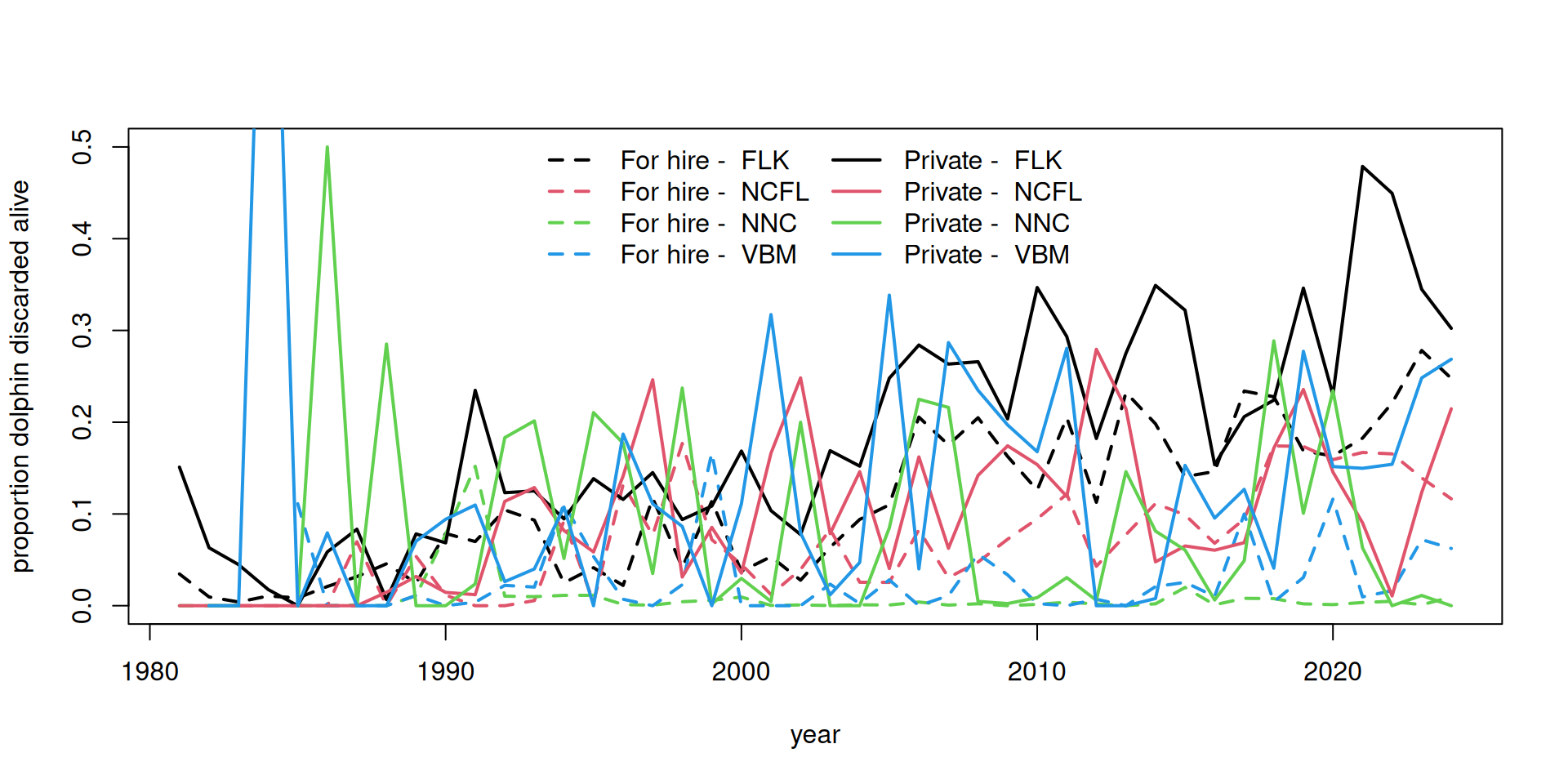
3.4 Looking at extent of discarding
Discard estimates (known as B2 estimates) are provided in numbers by the MRIP survey but are not available in the Southeast Region Headboat Survey. We can look at the overall numbers of dolphinfish caught versus reported released from the MRIP survey to get an understanding of the extent of discarding.
According to the MRIP survey and the reported numbers, discarding generally increases over time, excluding some highly anomalous estimates from the early years which are driven by low sample sizes. Discarding is generally higher in the private sector compared to the for-hire sector, and is highest in the Florida Keys region.
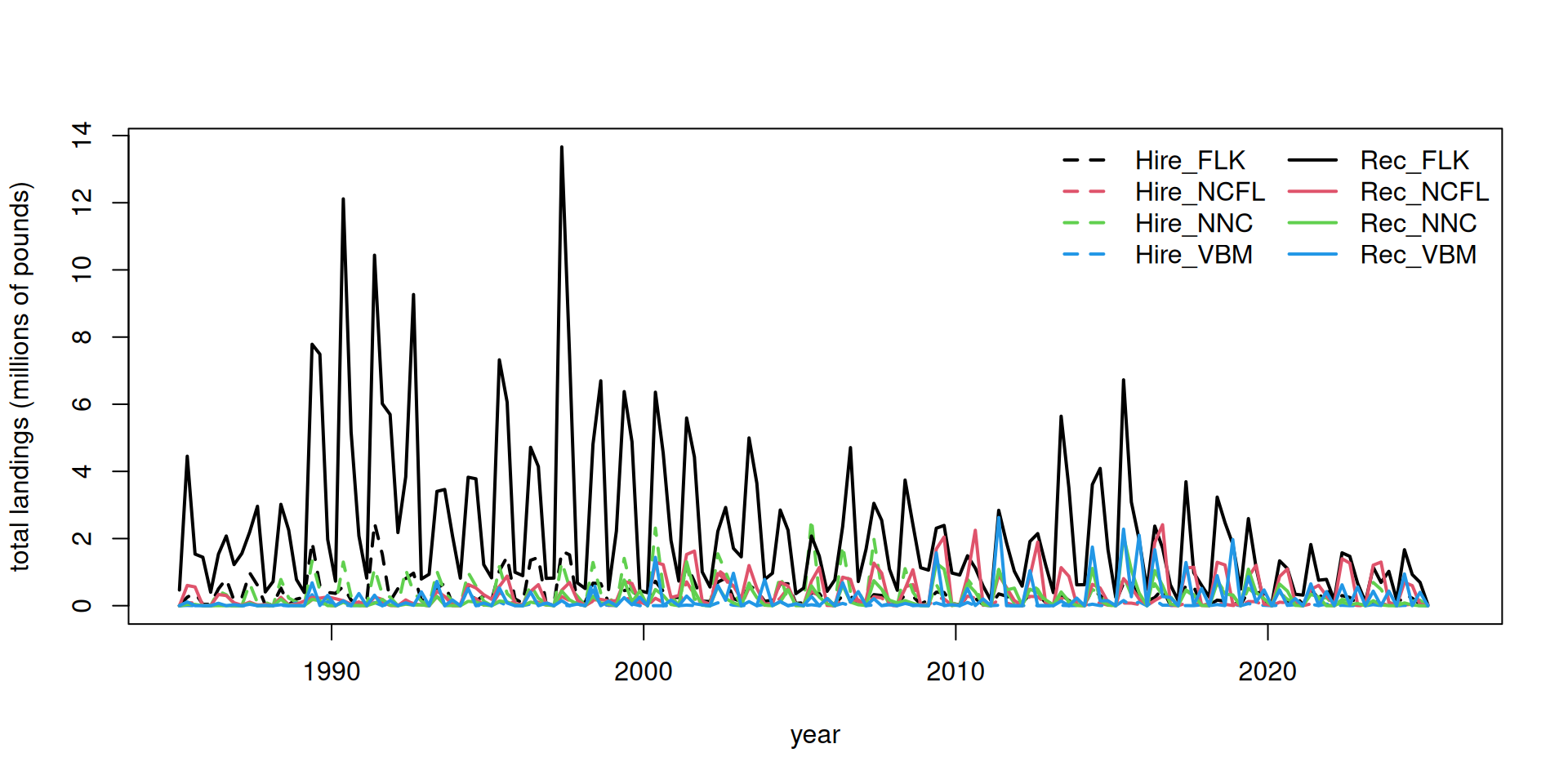
3.5 Split the landings by season
The dolphin MSE operates on a seasonal time step and thus the landings and discards must by parsed apart by individual season and year. This is not straightforward because MRIP estimates are reported in two-month waves (Jan - Feb, Mar - Apr, May - Jun, etc.), and the seasons are 3-month periods (Dec - Feb, Mar - May, Jun - Aug, Sep - Nov). For the two waves that have to be split into seasons (e.g., December is lumped with January and February; June is lumped with July and August), we split the wave 50/50%, i.e, we make the assumption that half of the landings in that wave occurs in one season and the other half occurs in the next season.
Hire_FLK Hire_NCFL Hire_NNC Hire_VBM Rec_FLK Rec_NCFL Rec_NNC
1981_2 NA NA NA NA 2793285.5 270968.46 NA
1981_3 300873.764 NA 254049.420 NA 3915698.3 NA NA
1981_4 50017.460 NA 2705.821 NA 905621.2 51537.26 NA
1981_5 3748.301 NA NA NA 479834.0 NA NA
1981_6 NA NA NA NA 848201.5 NA NA
1981_NA NA 74702.5 NA 1400.247 NA NA NA
Rec_VBM
1981_2 NA
1981_3 NA
1981_4 NA
1981_5 NA
1981_6 NA
1981_NA NA
f$YEAR <-as.numeric(substr(rownames(f), 1, 4))f$WAVE <-as.numeric(substr(rownames(f), 6, 8))head(f) # table with landings separated by wave and year
Hire_FLK Hire_NCFL Hire_NNC Hire_VBM Rec_FLK Rec_NCFL Rec_NNC
1981_2 NA NA NA NA 2793285.5 270968.46 NA
1981_3 300873.764 NA 254049.420 NA 3915698.3 NA NA
1981_4 50017.460 NA 2705.821 NA 905621.2 51537.26 NA
1981_5 3748.301 NA NA NA 479834.0 NA NA
1981_6 NA NA NA NA 848201.5 NA NA
1981_NA NA 74702.5 NA 1400.247 NA NA NA
Rec_VBM YEAR WAVE
1981_2 NA 1981 2
1981_3 NA 1981 3
1981_4 NA 1981 4
1981_5 NA 1981 5
1981_6 NA 1981 6
1981_NA NA 1981 NA
# deal with NAs in many locations ---------------# calculate percentages of landings by wave, for each region and fleetavw <-tapply(d1$LBSEST_SECWWT, list(d1$WAVE, d1$region, d1$sector), sum, na.rm = T)avw <- avw[-1, , ]avw <-data.frame(cbind(avw[, , 1], avw[, , 2]))names(avw) <-c("Hire_FLK", "Hire_NCFL", "Hire_NNC", "Hire_VBM", "Rec_FLK", "Rec_NCFL", "Rec_NNC", "Rec_VBM")avwp <-apply(avw, 2, function (x) x /sum(x, na.rm = T)) #colSums(avwp)# go through each column, find NAs and fill in waves by percentagespre_colsum <-colSums(f, na.rm = T) # column sums to check laterlis <-which(f$WAVE ==0) # list of rows with NA wave datafor (i in1:8) { # loop through each columnfor(j in lis) { # loop through list of NA wavesif (f[j, i] >0) { # if there are NA wave landings, split by known proportion from other years miscatch <- avwp[, i] * f[j, i] # missing landings are known proportion * NA wave landings f[which(f$YEAR == f$YEAR[j] & f$WAVE !=0), i] <- f[which(f$YEAR == f$YEAR[j] & f$WAVE !=0), i] + miscatch # add in missing landings f[j, i] <-0# set to zero after landings is attributed to waves } }}f[lis, 1:8] # should be all zeros now
f <- f[which(f$WAVE !=0), ] # remove NA waves which now contain no landings# split waves 3 and 6 50/50% to parse into seasons ------------------lis <-which(f$WAVE ==3| f$WAVE ==6) # list of 3 and 6 waves for all yearsfor (i in lis) { # go through list of waves temp <- f[i, ] /2# split landings in half temp[9] <- f$YEAR[i] # reformat year and wave data columns temp[10] <- f$WAVE[i] temp <-rbind(temp, temp) # create two half-waves and relabel with new wave reference number temp[1, 10] <- temp[1, 10] -0.5 temp[2, 10] <- temp[2, 10] +0.5 f <-rbind(f, temp) # concatenate with main data table }f <- f[-lis, ] # remove waves that have been split in halfpos_colsum <-colSums(f, na.rm = T) pre_colsum[1:8] == pos_colsum[1:8] # check that landings were parsed correctly - column sums should be identical
f <- f[order(f$YEAR, f$WAVE), ] # reorder table in chronological orderf$YEAR[which(f$WAVE ==6.5)] <- f$YEAR[which(f$WAVE ==6.5)] +1# add year to December wave so it gets summed with following yearf$WAVE[which(f$WAVE ==6.5)] <-0.5# change December wave to small number so it gets summed with Jan/Febtable(f$WAVE)
0.5 1 2 2.5 3.5 4 5 5.5
40 40 40 40 40 40 40 40
f$seas <-cut(f$WAVE, breaks =c(0, 1.5, 3, 4.5, 6))#table(f$seas)f$seas1 <-NAf$seas1[which(f$seas =="(0,1.5]")] <-"DJF"# Dec Jan Feb is 0.5 and 1f$seas1[which(f$seas =="(1.5,3]")] <-"MAM"# Mar Apr May is 2 and 2.5f$seas1[which(f$seas =="(3,4.5]")] <-"JJA"# Jun Jul Aug is 3.5 and 4f$seas1[which(f$seas =="(4.5,6]")] <-"SON"# Sep Oct Nov is 5 and 5.5temp <-tapply(f[, 1], list(f$seas1, f$YEAR), sum, na.rm = T)temp1 <-matrix(temp)for (i in2:8) { temp2 <-matrix(tapply(f[, i], list(f$seas1, f$YEAR), sum, na.rm = T)) temp1 <-cbind(temp1, temp2) }findat <-data.frame(sort(rep(as.numeric(colnames(temp)), 4)), rep(rownames(temp), ncol(temp)), temp1)names(findat) <-c("year", "season", names(f)[1:8])colSums(f[, 1:8], na.rm = T) ==colSums(findat[, 3:10], na.rm = T) # check that total landings are equal before and after parsing
# the values should be close but slightly >1 because the last data set includes December 1985 data as part of 1986colSums(findat[, 3:10], na.rm = T) /colSums(fin[-c(1:5), ], na.rm = T)